|
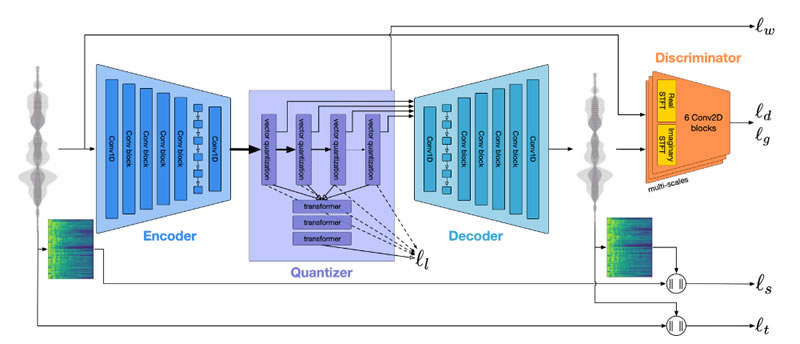
神经声码器采样端到端神经音频编解码框架,核心架构采用Encoder–Quantizer–Decoder三级结构。
算法在编码端通常基于一维卷积网络,将时域波形映射到低维连续潜在表示;随后通过残差向量量化(Residual Vector Quantization, RVQ)进行多级离散化,将连续表示压缩为有限码本索引,实现可控码率(如0.6–24 kbps);最后由对称结构的解码器重构时域波形。训练阶段采用端到端优化策略,损失函数通常包含多尺度STFT损失 + 感知对抗损失,判别器用于提升主观音质。
这种时域卷积自编码 + 残差向量量化压缩 + 感知对抗训练优化,适合设计低码率神经声码器。通过端到端的建模方式,结合频率域与时域的联合约束,使其在感知质量上显著优于传统参数化声码器。
|