| |
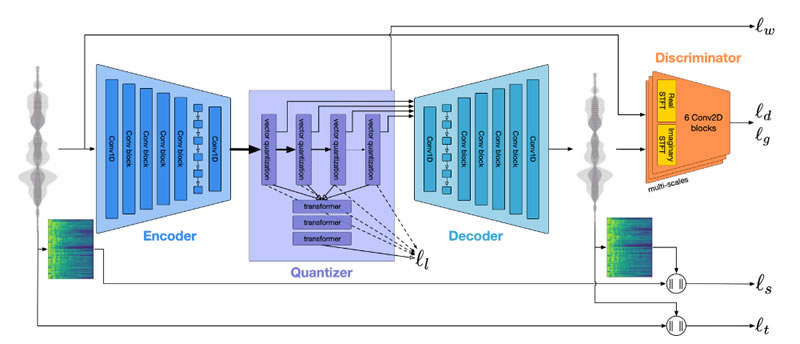
Neural vocoders adopt an end-to-end neural audio codec framework, with the core architecture featuring a three-stage Encoder쭯Quantizer쭯Decoder structure. At the encoding end, the algorithm is typically based on a one-dimensional convolutional network, mapping the time-domain waveform into a low-dimensional continuous latent representation. This is followed by multi-stage discretization using Residual Vector Quantization (RVQ), compressing the continuous representation into finite codebook indices to achieve a controllable bitrate (e.g., 0.6쭯24 kbps). Finally, a symmetrically structured decoder reconstructs the time-domain waveform. The training phase employs an end-to-end optimization strategy, with the loss function usually comprising multi-scale STFT loss + perceptual adversarial loss, where the discriminator is used to enhance subjective audio quality. This approach―time-domain convolutional autoencoding + residual vector quantization compression + perceptual adversarial training optimization―is well-suited for designing low-bitrate neural vocoders. Through end-to-end modeling, combined with joint constraints in both the frequency and time domains, it achieves significantly better perceptual quality compared to traditional parametric vocoders.
|
|